Spotify API Einführung
2021-11-30
Vorwort
Dieses Tutorial zeigt am Beispiel von Spotify wie eine API genutzt werden kann, um Daten zu sammeln, zu analysieren und darzustellen. Erleichtert wird dies durch das Package spotifyr.
Hilfreiche Dokumentationen sind hier zu finden:
- Spotify API Dokumentation - für Hintergrundinformationen, etc.
- Spotifyr Package Dokumentation - für eine Übersicht der Funktionen, Befehle und Parameter.
1 Setup
1.1 Einrichten der API
Um sich mit der Spotify API verbinden zu können, werden eine sogenannte SPOTIFY_CLIENT_ID und ein SPOTIFY_CLIENT_SECRET benötigt, die Spotify im Portal für Entwickler (Spotify for Developers) zur Verfügung stellt. Mit der Identifikationsnummer (Client ID) und dem geheimen, persönlichen Clientschlüssel (Secret) wird der Zugriff auf die API von Spotify dem API-Nutzer und seiner Anwendung zugeordnet.
Um ID und Clientschlüssel zu erhalten, müssen wir uns zunächst im Portal unter https://developer.spotify.com/dashboard/login anmelden und unseren Zugang einrichten. Dies ist entweder mit einem bereits bestehenden Spotify Konto möglich oder durch die Registrierung eines neuen (kostenfreien) Spotify Kontos.
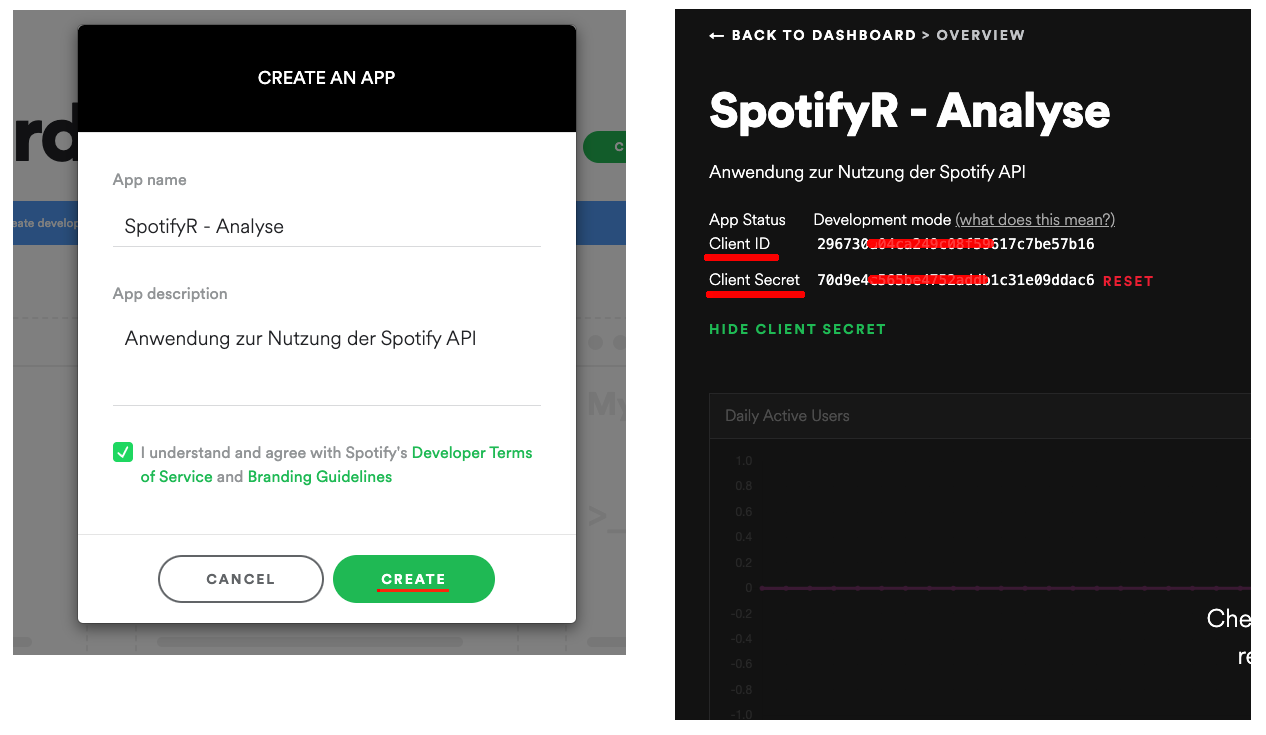
Nach erfolgreicher Anmeldung und Bestätigung der Vereinbarungen von Spotify erscheint ein Dashboard mit einer Übersicht über die von uns erstellten Apps im Portal. Da wir jedoch noch keine App erstellt haben, müssen wir dies nun über CREATE AN APP machen.

Im sich dann öffnenden Fenster müssen wir der Anwendung einen Namen und eine Beschreibung geben, den Bestimmungen von Spotify zustimmen und die Anwendung anschließend erstellen.
Damit erhalten wir ein weiteres Dashboard - diesmal für unsere neu erstellte Anwendung. Links über dem Dashboard finden wir so nun unsere Client ID und unter “Show Client Secret” unser Client Secret, also unseren persönlichen Zugangsschlüssel. Beide werden wir später in R einfügen müssen, um eine Verbindung zu unserer Anwendung und damit der Spotify API aufzubauen. Beide sind prinzipiell vertraulich zu behandeln, da mit ihnen praktisch jeder über die auf unser Konto registrierte Anwendung auf die Spotify API zugreifen kann und damit theoretisch auch Handlungen durchführen könnte, die den Nutzungsbedingungen von Spotify widersprechen.
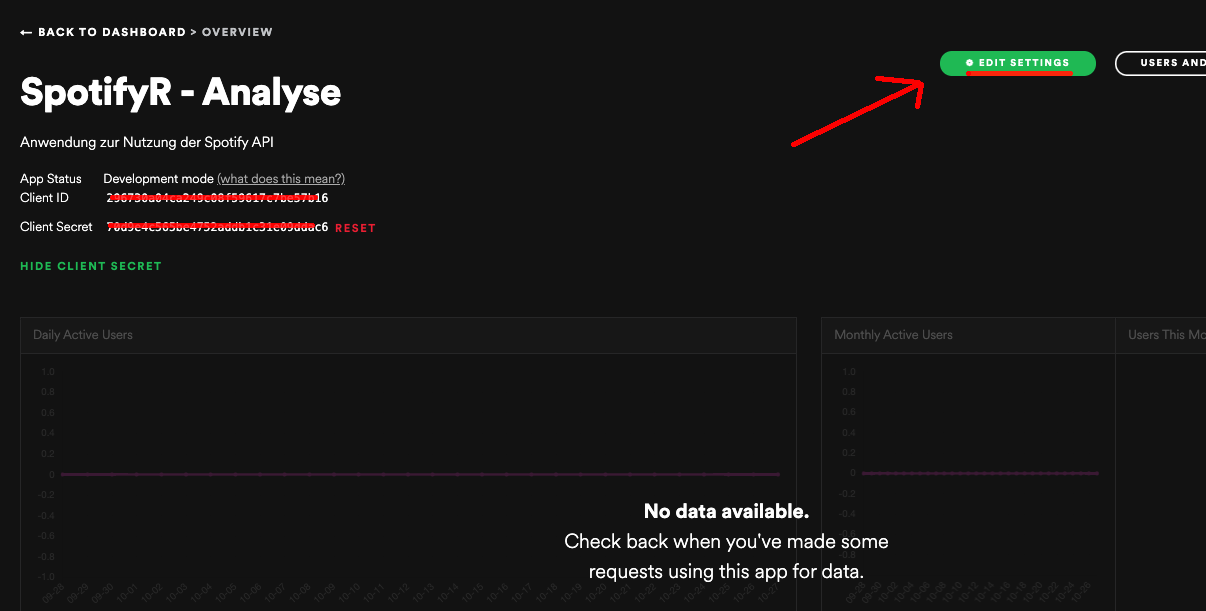
Bevor wir in R starten können, ist zudem noch eine weitere Einstellung nötig. Da es für bestimmte Funktionen und Anwendungen erforderlich ist, sich bei Spotify einzuloggen, muss eine Rückverbindung zwischen unserer Anwendung und der API hergestellt werden. Um diese einzurichten, müssen wir unter EDIT SETTINGS die Einstellungen öffnen.
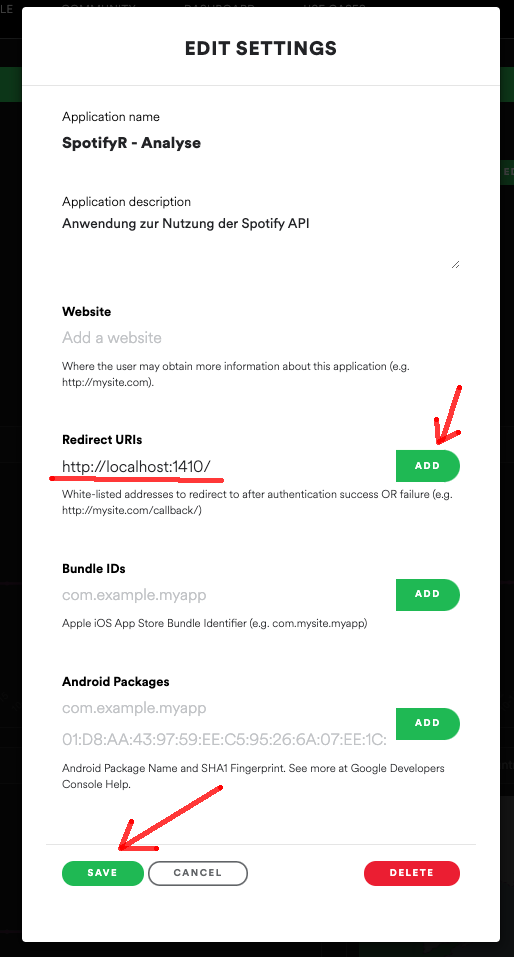
Anschließend müssen wir in den Einstellungen die Adresse:
in das Feld Redirect URIs eingetragen. Anschließend sind die Einstellungen zu speichern.
1.2 Libraries
Nun können wir unser R-Projekt anlegen und die für unser Projekt notwendigen Libraries laden.
Diese Libraries werden im Folgenden verwendet:
- spotifyr - um die Verbindung zu unserer Spotify-Anwendung herzustellen und Daten über die im Package enthaltenen Funktionen zu erhalten
- ggplot2 - um Diagramme anzufertigen und unsere Daten zu visualisieren
- dplyr - um unseren Datensatz gruppieren und filtern zu können
- purrr - wird in der Datenbereinigung verwendet
library(spotifyr)
library(ggplot2)
library(dplyr)
library(purrr)2 Playlist Analysen
Mit der nun hergestellten Verbindung können wir jegliche Funktionen des spotifyr Packages nutzen und beispielsweise Daten zu Künstlern, Alben, Playlisten oder Labels von Spotify abfragen. Eine Übersicht zu den möglichen Funktionen ist in der spotifyr Dokumentation zu finden:
- Spotifyr Package Dokumentation - für eine Übersicht der Funktionen, Befehle und Parameter.
Playlisten sind heutzutage das zentrale Element in der Art und Weise wie Musik konsumiert wird. Ganz egal ob es sich dabei um hauseigene, von Spotify kuratierte Playlisten oder um von anderen Nutzern oder uns selbst erstellte Playlisten handelt, spotifyr ermöglicht uns den Zugang zu unterschiedlichsten Daten über diese Playlisten.
Diese Daten erhalten wir unter anderem durch folgende Funktionen:
- get_category_playlists() - gibt eine Liste von Playlisten, mit einer bestimmten Kategorie getagged werden aus
- get_playlist_cover_image() - lädt das Cover-Bild einer Playlist
- get_playlist_tracks() - lädt Details zu den Songs in einer Playlist
- get_playlist_audio_features() - lädt Meta-Daten sowie Audio-Analyse-Daten der Songs einer Playlist
2.1 Datenbeschaffung
Um eine Playlist zu analysieren, benötigen wir nun lediglich die Playlist URI, die sich im Link einer jeden Playlist befindet und den Namen des Profils, welches die Playlist erstellt hat. Dazu können wir im Browser oder in der Spotify Desktop-App über die drei kleinen Punkte in der Menüleiste der Playlist zum Link gelangen.
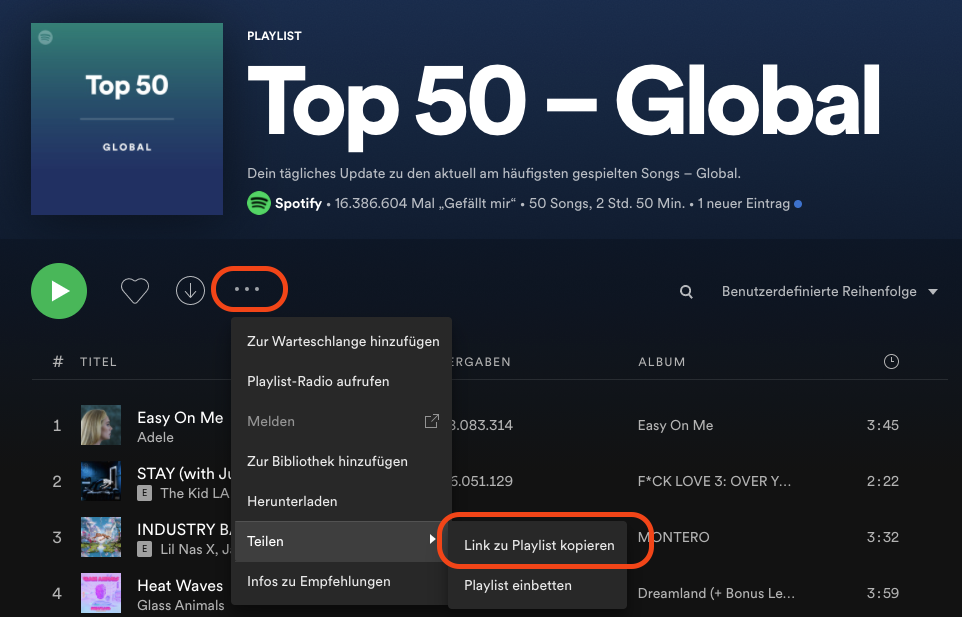
Ich habe mich hier für die “Top 50 - Global” Playlist von Spotify entschieden. Der vollständige Link zur Playlist ist: https://open.spotify.com/playlist/37i9dQZEVXbMDoHDwVN2tF?si=95eadb888fe644fc
Aus dieser URL kann ich nun die URI kopieren. Sie setzt sich aus den Zeichen ab playlist/ bis zum ? zusammen. Also aus der hier markierten Zeichenfolge:
…open.spotify.com/playlist/37i9dQZEVXbMDoHDwVN2tF?si=95eadb888fe644fc
Zusammen mit dem Namen des Profils welches die Playlist erstellt hat (in diesem Fall Spotify), können wir nun ein Dataframe mit dem Titel playlist_dataframe erstellen und die Daten der Playlist über die Funktion get_playlist_audio_features() abfragen.
Wichtiger Hinweis: Da wir mit der “Top 50 - Global” Playlist eine sich täglich aktualisierende Playlist ausgewählt haben, können die Ergebnisse und Songs beim “selber ausprobieren” von denen des Tutorials abweichen.
playlist_username <- "Spotify"
playlist_uris <- c("37i9dQZEVXbMDoHDwVN2tF")
playlist_dataframe <- get_playlist_audio_features(playlist_username, playlist_uris)Über die Funktion colnames() können wir uns nun anschauen, welche Variablen und damit welche Informationen dieser Datensatz enthält. Neben typischen Meta-Daten wie dem Songnamen in der Spalte track.name, der URI der einzelnen Songs in der Spalte track.uri oder dem Tag, an dem der Song der Playlist hinzugefügt wurde, in der Spalte added_at, beinhaltet unser Datensatz unter Anderem Audioanalysen, Links und Informationen über die Länder in denen der Song verfügbar ist.
colnames(playlist_dataframe)## [1] "playlist_id" "playlist_name"
## [3] "playlist_img" "playlist_owner_name"
## [5] "playlist_owner_id" "danceability"
## [7] "energy" "key"
## [9] "loudness" "mode"
## [11] "speechiness" "acousticness"
## [13] "instrumentalness" "liveness"
## [15] "valence" "tempo"
## [17] "track.id" "analysis_url"
## [19] "time_signature" "added_at"
## [21] "is_local" "primary_color"
## [23] "added_by.href" "added_by.id"
## [25] "added_by.type" "added_by.uri"
## [27] "added_by.external_urls.spotify" "track.artists"
## [29] "track.available_markets" "track.disc_number"
## [31] "track.duration_ms" "track.episode"
## [33] "track.explicit" "track.href"
## [35] "track.is_local" "track.name"
## [37] "track.popularity" "track.preview_url"
## [39] "track.track" "track.track_number"
## [41] "track.type" "track.uri"
## [43] "track.album.album_type" "track.album.artists"
## [45] "track.album.available_markets" "track.album.href"
## [47] "track.album.id" "track.album.images"
## [49] "track.album.name" "track.album.release_date"
## [51] "track.album.release_date_precision" "track.album.total_tracks"
## [53] "track.album.type" "track.album.uri"
## [55] "track.album.external_urls.spotify" "track.external_ids.isrc"
## [57] "track.external_urls.spotify" "video_thumbnail.url"
## [59] "key_name" "mode_name"
## [61] "key_mode"2.2 Datenbereinigung
Bevor erste Analysen angefertigt werden können, sollte zunächst ein genauerer Blick auf den vorliegenden Datensatz geworfen werden. Um sehen zu können, welche die ersten 5 Songs in der Playlist sind und von welchen Künstler diese Songs können wir folgenden Befehl ausführen:
playlist_dataframe[1:5, c("track.name","track.artists")]## # A tibble: 5 x 2
## track.name track.artists
## <chr> <list>
## 1 Easy On Me <df[,6] [1 × 6…
## 2 STAY (with Justin Bieber) <df[,6] [2 × 6…
## 3 INDUSTRY BABY (feat. Jack Harlow) <df[,6] [2 × 6…
## 4 abcdefu <df[,6] [1 × 6…
## 5 All Too Well (10 Minute Version) (Taylor's Version) (From The… <df[,6] [1 × 6…Hier stellen wir jedoch fest, dass der Eintrag in der Spalte track.artists für jeden Song aus einem weiteren Dataframe besteht. Zusätzlich sehen wir, dass die Dimensionen dieser Dataframes variieren. Bei genauerer Betrachtung eines solchen Eintrags können wir jedoch feststellen, dass in diesen Dataframes neben dem Künstlernamen auch die URL zum Profil des Künstlers, seine ID und weitere Informationen verborgen sind.
Um unseren Datensatz besser aufzubereiten, können wir mit der Funktion map_chr() aus der Library purr() für jede Zeile in unserem Datensatz den ersten Eintrag in der Variable name extrahieren und einer neuen Spalte mit dem Titel main_artist hinzufügen.
So können wir nun neben dem Songtitel direkt den Künstlernamen des in den Songdaten zuerst genannten Künstlers erhalten.
playlist_dataframe$main_artist <- map_chr(playlist_dataframe$track.artists, function(x) x$name[1])
playlist_dataframe[1:5, c("track.name","main_artist")]## # A tibble: 5 x 2
## track.name main_artist
## <chr> <chr>
## 1 Easy On Me Adele
## 2 STAY (with Justin Bieber) The Kid LAR…
## 3 INDUSTRY BABY (feat. Jack Harlow) Lil Nas X
## 4 abcdefu GAYLE
## 5 All Too Well (10 Minute Version) (Taylor's Version) (From The Va… Taylor SwiftIn der Spalte track.album.release_date können wir das Erscheinungsdatum der Songs einsehen. Da die in dieser Spalte enthaltenen Werte jedoch das Format character haben und wir uns in den folgenden Analysen eher für das Erscheinungsjahr und nicht für den genauen Tag interessieren, können wir eine neue Spalte für das Erscheinungsjahr anlegen und das Datum in das Format “%Y” konvertieren. Wir nennen diese Spalte release_year.
playlist_dataframe$release_year <- format(as.Date(playlist_dataframe$track.album.release_date), format="%Y")
playlist_dataframe[1:5, c("track.name","main_artist","release_year")]## # A tibble: 5 x 3
## track.name main_artist release_year
## <chr> <chr> <chr>
## 1 Easy On Me Adele 2021
## 2 STAY (with Justin Bieber) The Kid LAR… 2021
## 3 INDUSTRY BABY (feat. Jack Harlow) Lil Nas X 2021
## 4 abcdefu GAYLE 2021
## 5 All Too Well (10 Minute Version) (Taylor's Version)… Taylor Swift 2021Aufgrund des Umfangs unseres Datensatzes besteht außerdem Kürzungspotenzial. Für weitere Analysen könnte man sich nun einen weiteren Datensatz einrichten, der nur die zu untersuchenden Variablen erhält. Um hier jedoch Spielraum für Kreativität zu lassen, sehen wir an dieser Stelle davon ab.
2.3 Explorative Datenanalyse
2.3.1 Erscheinungsjahre
Da wir bereits eine Spalte für das Erscheinungsjahr erstellt haben, können wir uns nun anschauen, wieviele Songs unserer Playlist aus welchen Jahren stammen.
Für die Darstellung nutzen wir hier die Library ggplot2.
Mit den Funktionen labs() und geom_text() können wir das Diagramm beschriften und uns die Summe der Songs pro Jahr über jedem Balken anzeigen lassen.
library(ggplot2)
release_year_plot <- ggplot(playlist_dataframe, aes(x=release_year)) +
geom_bar() +
labs(title = "Songs pro Erscheinungsjahr in den Spotify Global Top-50 am 24.11.21:") +
geom_text(aes(label = ..count..), stat = "count", vjust = -0.2, colour = "black") +
labs(x= "Erscheinungsjahr", y= "Anzahl der Songs")
release_year_plot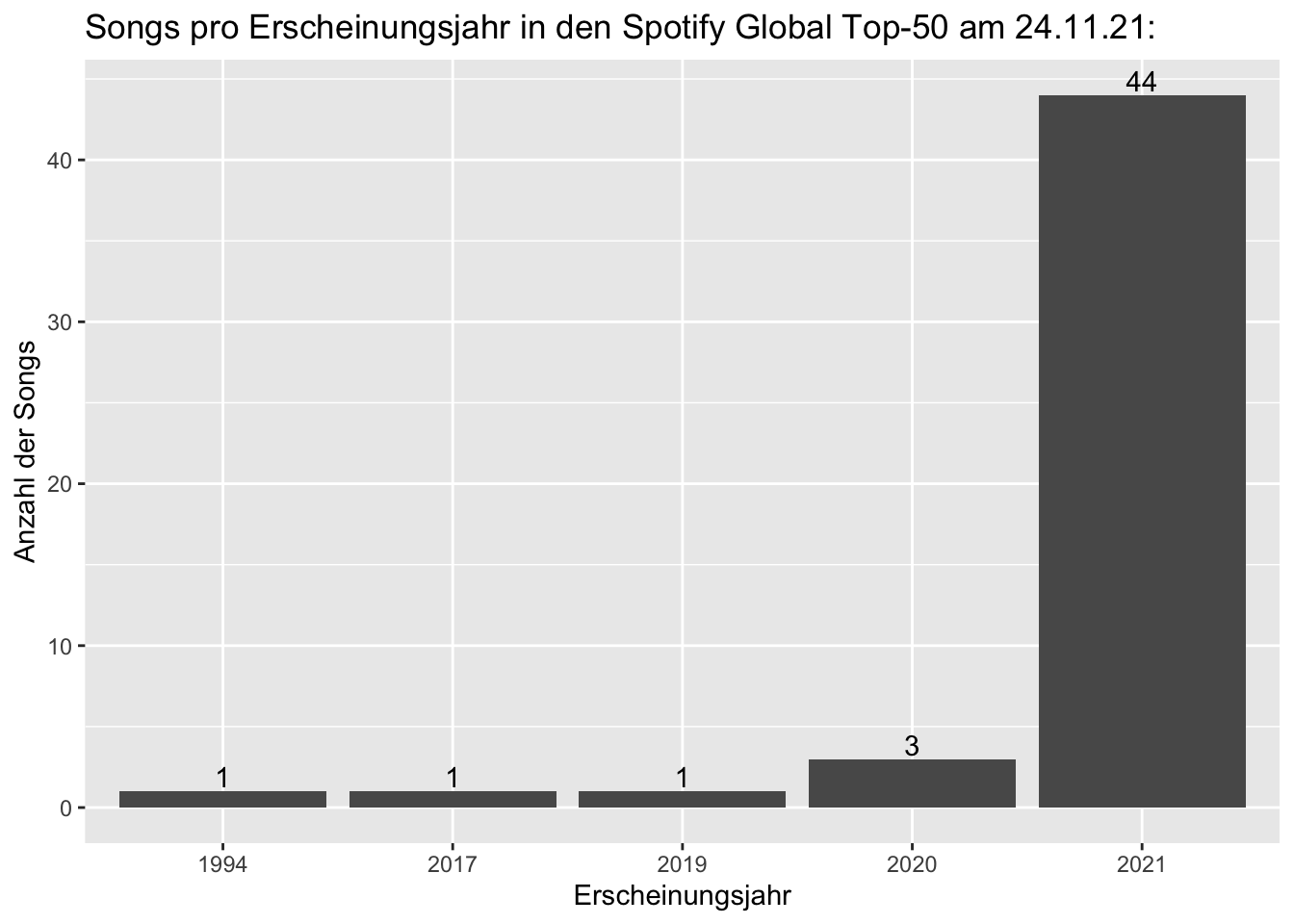
Möchte ich nun wissen, welcher Song es ist, der in 1994 erschienen und dennoch in der heutigen Top-50 Playlist enthalten ist, kann ich dies über den folgenden Befehl erfahren:
playlist_dataframe[playlist_dataframe$release_year=="1994", c("track.name","main_artist")]## # A tibble: 2 x 2
## track.name main_artist
## <chr> <chr>
## 1 All I Want for Christmas Is You Mariah Carey
## 2 <NA> <NA>2.3.2 Audioanalysen
In unserem Datensatz befinden sich mehrere Variablen aus den Audioanalysen, die Spotify für jeden einzelnen Song angefertigt hat und zudem im Empfehlungsalgorithmus verwendet. Dazu zählen neben dem Tempo (in Schläge pro Minute), der Tonart und der Taktart auch Werte für die folgenden Aspekte:
- Tanzbarkeit (danceability) auf einer Skala von 0 bis 1
- Akustik (acousticness) auf einer Skala von 0 bis 1
- Energie/Kraft (energy) auf einer Skala von 0 bis 1
- Instrumentalität (instrumentalness) auf einer Skala von 0 bis 1 - wobei Songs mit Werten über 0.5 als Songs ohne Gesang/Rap vermutet werden
- Liveness auf einer Skala von 0 bis 1 - wobei ein höherer Wert für eine höhere Wahrscheinlichkeit steht, dass der Song live performed wurde
- Lautheit (loudness) in Dezibel, typischerweise zwischen -60 und 0 dB
- speechiness auf einer Skala von 0 bis 1 - als Indikator, ob sich im Song gesprochene Worte befinden
- Valenz (valence) auf einer Skala von 0 bis 1 - wobei ein höherer Wert für einen positiveren Klang steht
Um ein paar dieser Aspekte zu untersuchen, bietet sich eine deskriptive Übersicht an. Dabei zeigt sich zum Beispiel, dass Songs in der Top-50 Global Playlist eine eher höhere Tanzbarkeit und eher niedrigere Werte für den Aspekt Akustik aufweisen.
summary(playlist_dataframe[c("danceability", "liveness", "speechiness", "valence", "energy", "acousticness","tempo")])## danceability liveness speechiness valence
## Min. :0.2340 Min. :0.02640 Min. :0.02820 Min. :0.0849
## 1st Qu.:0.5655 1st Qu.:0.08843 1st Qu.:0.03765 1st Qu.:0.3380
## Median :0.6415 Median :0.12000 Median :0.04880 Median :0.5045
## Mean :0.6263 Mean :0.18032 Mean :0.07596 Mean :0.5047
## 3rd Qu.:0.7400 3rd Qu.:0.31950 3rd Qu.:0.08390 3rd Qu.:0.6775
## Max. :0.8700 Max. :0.50500 Max. :0.36300 Max. :0.9470
## energy acousticness tempo
## Min. :0.1580 Min. :0.00146 Min. : 67.2
## 1st Qu.:0.5192 1st Qu.:0.04605 1st Qu.: 95.5
## Median :0.6315 Median :0.24800 Median :120.0
## Mean :0.6121 Mean :0.30162 Mean :123.6
## 3rd Qu.:0.7368 3rd Qu.:0.49625 3rd Qu.:148.1
## Max. :0.8930 Max. :0.90800 Max. :201.7Wir können uns nun beispielsweise anschauen, welche Songs in der Playlist die besonders hohen Werte für die Tanzbarkeit aufweisen. Erneut greifen wir dabei auf die Library ggplot2 zu, benutzen dieses Mal jedoch auch die Library dplyr, um unseren Datensatz gruppieren und filtern zu können.
Den Filter setzen wir hier auf danceability >= 0.75, um nur Ergebnisse für Songs zu erhalten, deren Tanzbarkeit mindestens 0.75 beträgt. Über die Funktionen labs() und ggtitle können wir unser Diagramm beschriften. Die Funktion theme() ermöglicht es uns, die Beschriftung der x-Achse für eine bessere Lesbarkeit um 90 Grad zu drehen.
playlist_dataframe %>%
group_by(danceability) %>%
filter(danceability >= 0.75) %>%
ggplot(aes(x = track.name, y = danceability)) +
geom_col(aes(fill = track.name)) +
labs(x= "Songname", y= "Danceability", fill= "Songtitel") +
ggtitle("Welche Songs in den Top-50 Global haben die höchste Tanzbarkeit?", "Songs mit einer danceability >= 0.75") +
theme(axis.text.x = element_text(angle = 90))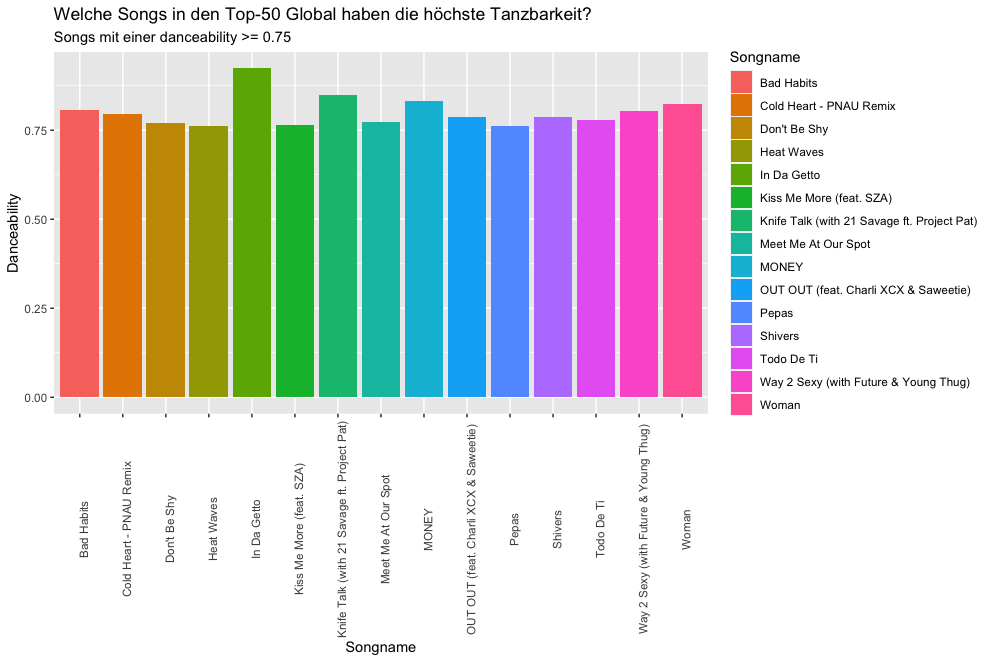
Möchten wir uns nun anschauen, welche Tonarten in der Playlist vertreten sind, können wir dies mit der Variable key_mode und der Funktion ggplot().
key_plot <- ggplot(playlist_dataframe, aes(x=key_mode)) +
geom_bar() +
labs(title = "Anzahl der Songs nach Tonart in den Spotify Global Top-50 am 24.11.21:") +
geom_text(aes(label = ..count..), stat = "count", vjust = -0.2, colour = "black") +
labs(x= "Tonart", y= "Anzahl der Songs") +
theme(axis.text.x = element_text(angle = 90))
key_plot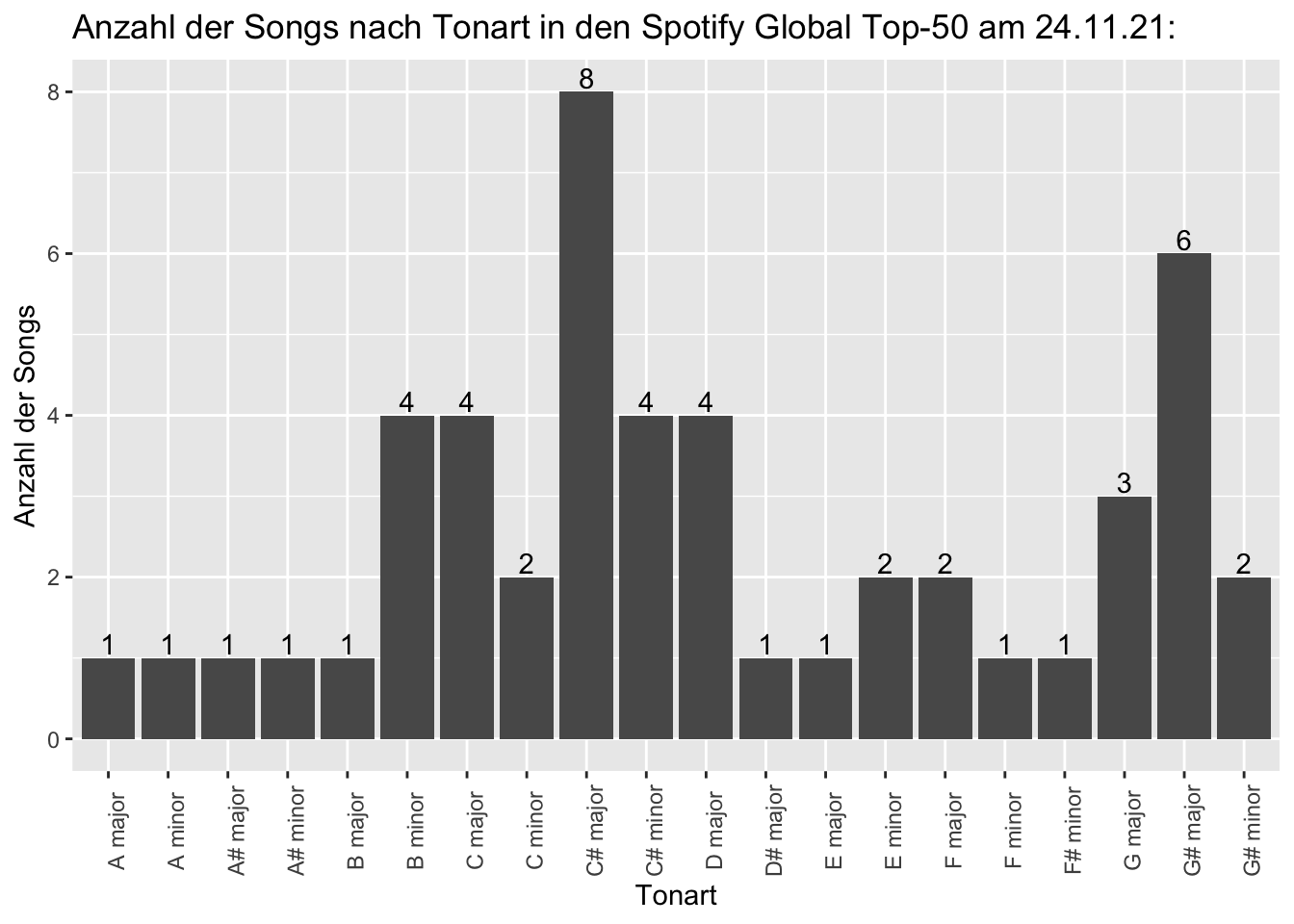
In vielen Fällen sind die Songs in einer Playlist aufeinander abgestimmt, beispielsweise um ein Genre (Rap Caviar, Electronic Rising, Dance Brandneu), einen Anlass (Partyhymnen, Christmas Hits), eine bestimmte Zeit (All Out 90s) oder Ähnliches abzubilden.
Ob bewusst oder unbewusst, meistens entscheiden wir uns doch für Playlisten aufgrund ihrer Stimmung. Möchten wir nun wissen, welchen Stimmungen sich die Songs einer Playlist zuordnen lassen und so vielleicht auch mehr über unsere persönlichen Präferenzen herausfinden, können wir die Variablen energy und valence aus den Audioanalysen verwenden. Spotify defininert die beiden Variablen wie folgt:
Valence:
A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry).
Energy:
Energy is a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale. Perceptual features contributing to this attribute include dynamic range, perceived loudness, timbre, onset rate, and general entropy.
Mit diesen beiden Variablen können wir also ein Streudiagramm erstellen und in Quadranten einteilen. Dabei können wir festlegen, dass wir Songs mit hoher Valenz (happy, cheerful, euphoric) und hoher Energie (fast, loud, and noisy) als Joyful / Happy bezeichnen würden, während Songs mit niedriger Valenz (sad, depressed, angry) und niedriger Energie eher Depressing / Sad beschrieben werden können.
Songs mit einer hohen Energie, aber einer niedrigen Valenz können wir als Angry / Turbulent und Songs mit einer niedrigen Energie, aber hohen Valenz als Peace / Chill beschreiben.
Mit dem folgenden Code erhalten wir einen emotionalen Quadranten, der uns Aufschluss über die Stimmung unserer ausgewählten Playlist gibt.
emotionalQuadrant <- ggplot(data = playlist_dataframe, aes(x = valence, y = energy)) +
geom_jitter(size = 0.8) +
geom_vline(xintercept = 0.5) +
geom_hline(yintercept = 0.5) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
scale_y_continuous(expand = c(0, 0), limits = c(0, 1)) +
annotate("text", 0.25 / 2, 0.95, label = "Angry / Turbulent") +
annotate("text", 1.75 / 2, 0.95, label = "Joyful / Happy") +
annotate("text", 1.75 / 2, 0.05, label = "Peace / Chill") +
annotate("text", 0.25 / 2, 0.05, label = "Depressing / Sad") +
labs(x= "Valence", y= "Energy") +
ggtitle("Emotional quadrant of chosen playlist", "Based on energy and valence")
emotionalQuadrant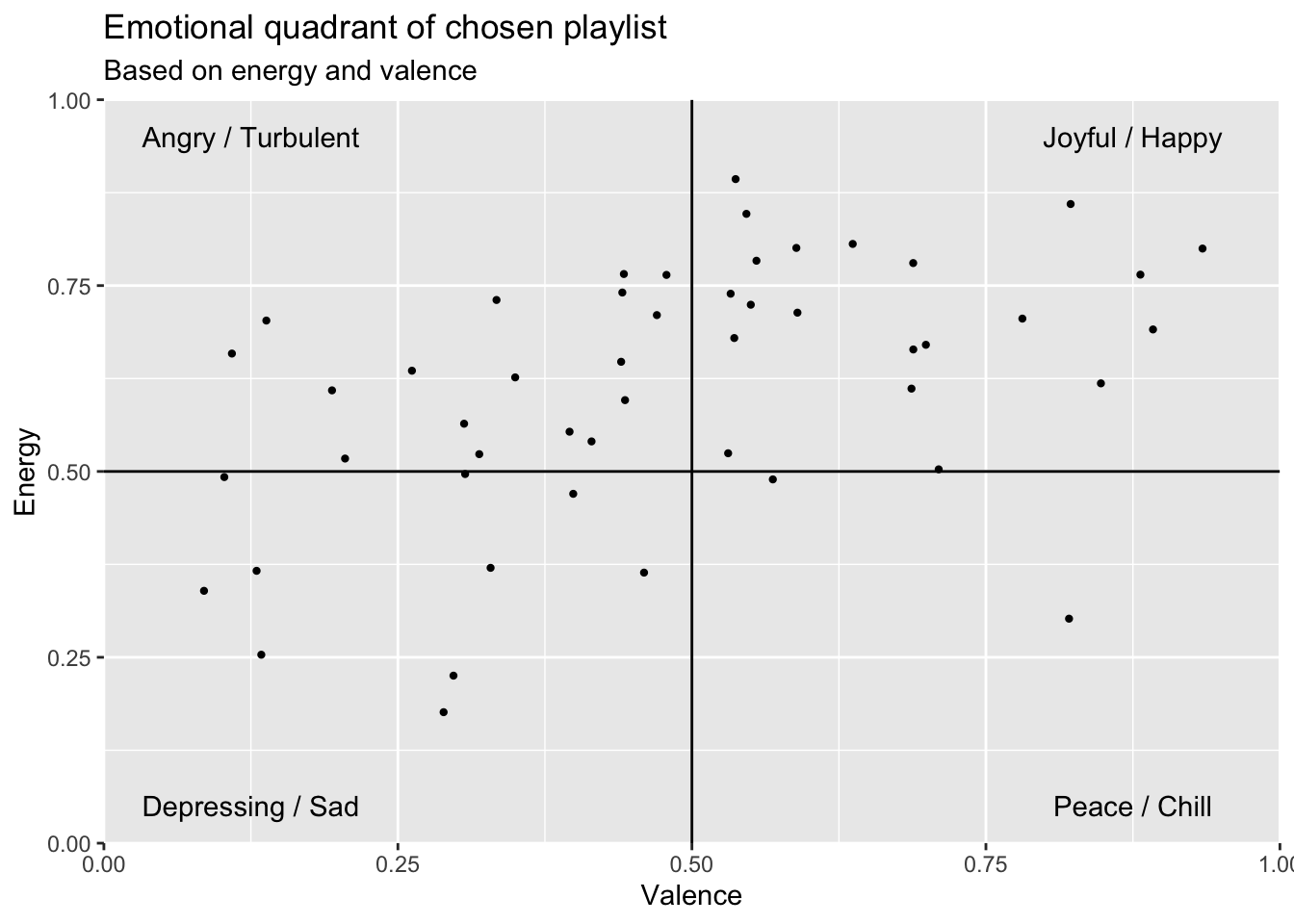
3 Artist Analysen
Für Daten zu Künstlern bietet spotifyr ebenfalls eine Vielzahl an Funktionen. Diese umfassen unter anderem:
- get_artist_audio_features() - für die Audio-Analysen der gesamten Diskographie
- get_artist_albums() - für Meta-Informationen des Katalogs
- get_artist_top_tracks() - für die Top-Songs des Künstlers innerhalb eines bestimmten Marktes/Land
- get_related_artists() - für Informationen über ähnliche Künstler, basierend auf dem vergangenen Hörverhalten der Spotify-Nutzer
3.1 Related Artists
Um zu untersuchen, welche Artists basierend auf dem Hörverhalten der Spotify-Nutzer mit einem von uns gewählten Artists in Verbindung stehen, benötigen wir lediglich die ID des Artists.
Diese können wir entweder wie bei den Playlisten aus dem Link des Artistprofils über Spotify kopieren oder sie aus den artist audio features ziehen, für die wir lediglich den Namen benötigen. Wir können also die Funktion get_artist_audio_features() auf einen beliebigen Namen anwenden und die Spalte artist_id abrufen. Da unser Datensatz artist_data jedoch aus allen Songs des Artists besteht und wir die ID nur einmal benötigen, müssen wir durch die Erweiterung [1] den Eintrag in der ersten Zeile wählen.
artist_data <- get_artist_audio_features(artist="Travis Scott")
artist_data$artist_id[1]## [1] "0Y5tJX1MQlPlqiwlOH1tJY"Nun können wir die artist_id für die Funktion get_related_artists() nutzen und erhalten einen Datensatz mit Informationen zu den aufgrund von Nutzungsdaten der Spotify-User ähnlichen Künstlern.
related_artists <- get_related_artists(
artist_data$artist_id[1],
include_meta_info = FALSE
)
related_artists$name## [1] "A$AP Rocky" "Chief Keef" "Joey Bada$$"
## [4] "A$AP Ferg" "Playboi Carti" "Huncho Jack"
## [7] "Pusha T" "Kendrick Lamar" "A$AP Mob"
## [10] "Chance the Rapper" "Meek Mill" "Metro Boomin"
## [13] "ScHoolboy Q" "Kodak Black" "Young Nudy"
## [16] "Gunna" "Quavo" "Lil Uzi Vert"
## [19] "Childish Gambino" "Migos"Aus unserem neuen related_artists Datensatz können wir zudem die popularity der Künstler entnehmen und mit dem folgenden Code vergleichbar darstellen.
related_artists_plot <- ggplot(related_artists, aes(x=name, y=popularity)) +
geom_bar(stat = "identity") + # Y axis is explicit. 'stat=identity'
geom_col(aes(fill = name), show.legend = FALSE) +
labs(x= "Artist", y= "Popularity") +
ggtitle("Wie populär sind Künstler die Spotify mit Travis Scott assoziiert?","Basierend auf dem Hörverhalten der Spotify User") +
theme(axis.text.x = element_text(angle = 90))
related_artists_plot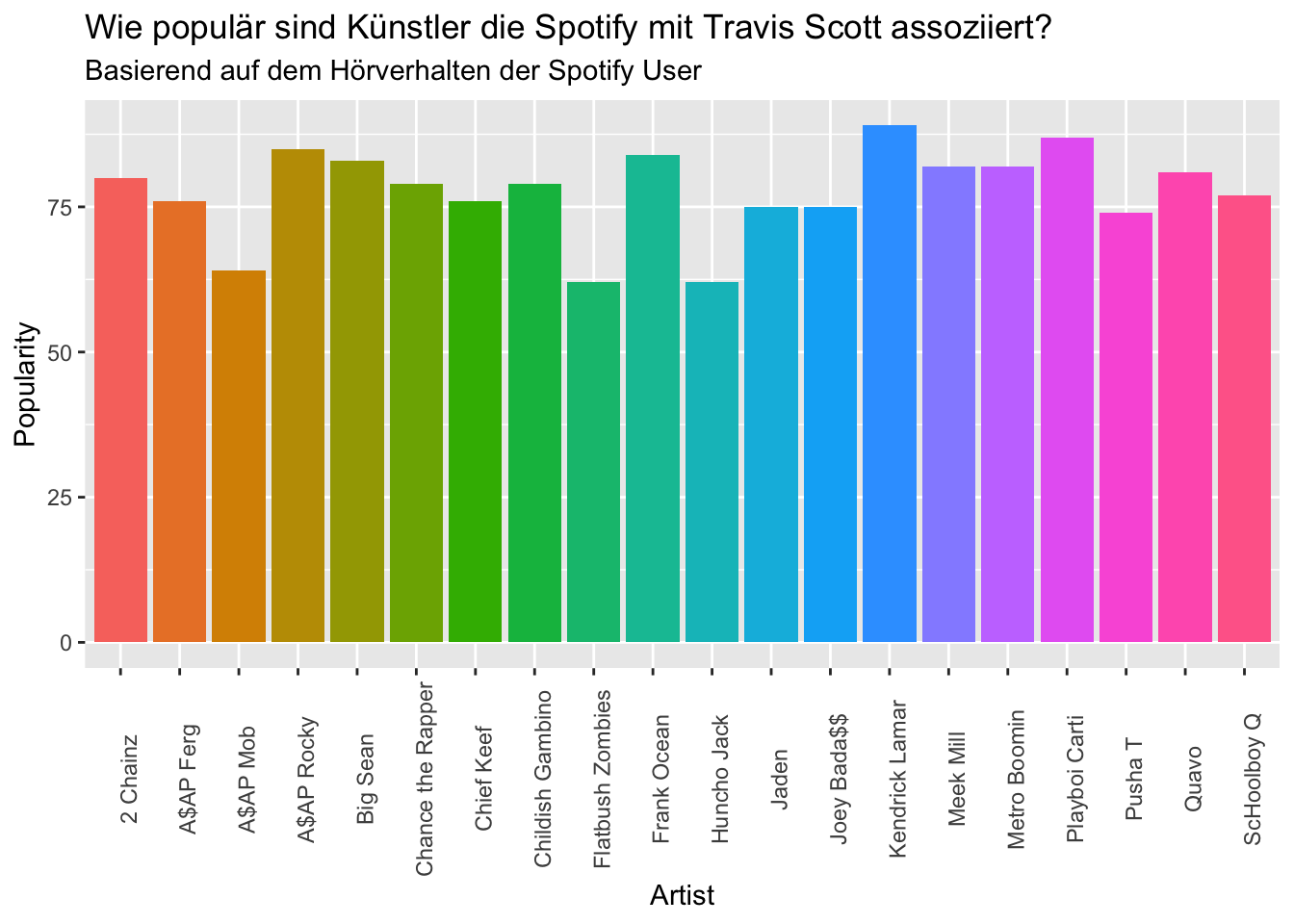
3.2 Artist Vergleich
Möchten wir nun beliebig viele Artists mit Hilfe der Funktion get_artist_audio_features miteinander vergleichen, können wir uns einfach eine Liste beliebiger Artists erstellen und die Funktion in einer for-Schleife anwenden.
Vor der Schleife generieren wir zunächst einen leeren Datensatz mit dem Namen artist_comparison. In der for-Schleife führen wir dann solange die folgenden Aktionen durch, bis jeder Eintrag in unserer artist_names-Liste verwendet worden ist.
Mit dem Befehl for (i in 1:length(artist_names)) sagen wir also, dass die darauf folgenden Aktionen für jede Nummer i in dem Intervall von 1 bis 5 (also der Anzahl der Einträge in unserer artist_names Liste) durchgeführt werden sollen.
Die Aktionen, die wir dann für jede Nummer von 1 bis 5 durchführen umfassen:
- die Erstellung des Datensatzes artist_data mit der Funktion get_artist_audio_features für den jeweiligen Artist aus unserer Liste
- das Zusammenfügen unseres artist_comparison Datensatzes mit dem neuen artist_data Datensatz
- das Ausgeben des Künstlernamens des im jeweiligen Durchlauf verwendeten Artists. Diese Ausgabe dient nur zu dem Zweck, den Fortschritt unserer Schleife zu überprüfen
Zusammengefasst nimmt unsere for-Schleife also jedes Mal einen Artistnamen, verwendet ihn für die get_artist_audio_features Funktion und fügt die neuen künstlerspezifischen Daten unserem gesamten artist_comparison Datensatz hinzu.
artist_names <- c("Adele","The Weeknd", "Billie Eilish", "Skrillex", "Dua Lipa")
artist_comparison <- data.frame()
for (i in 1:length(artist_names)) {
artist_data <- get_artist_audio_features(artist= artist_names[i])
artist_comparison <- rbind(artist_comparison, artist_data)
print(artist_names[i])
}Nun können wir wie zuvor bei den Playlisten verschiedene Analysen zu den von uns gewählten Artists durchführen. So können wir beispielsweise erneut einen emotionalen Qudaranten erstellen und diesmal farblich zwischen den Artists unterscheiden.
emotionalQuadrant_top_artists <- ggplot(data = artist_comparison, aes(x = valence, y = energy, color = artist_name)) +
geom_jitter(size = 0.8) +
geom_vline(xintercept = 0.5) +
geom_hline(yintercept = 0.5) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
scale_y_continuous(expand = c(0, 0), limits = c(0, 1)) +
annotate("text", 0.25 / 2, 0.95, label = "Angry / Turbulent") +
annotate("text", 1.75 / 2, 0.95, label = "Joyful / Happy") +
annotate("text", 1.75 / 2, 0.05, label = "Peace / Chill") +
annotate("text", 0.25 / 2, 0.05, label = "Depressing / Sad") +
labs(x= "Valence", y= "Energy", color = "Artist") +
ggtitle("Emotional quadrant of selected artists", "Based on energy and valence")
emotionalQuadrant_top_artists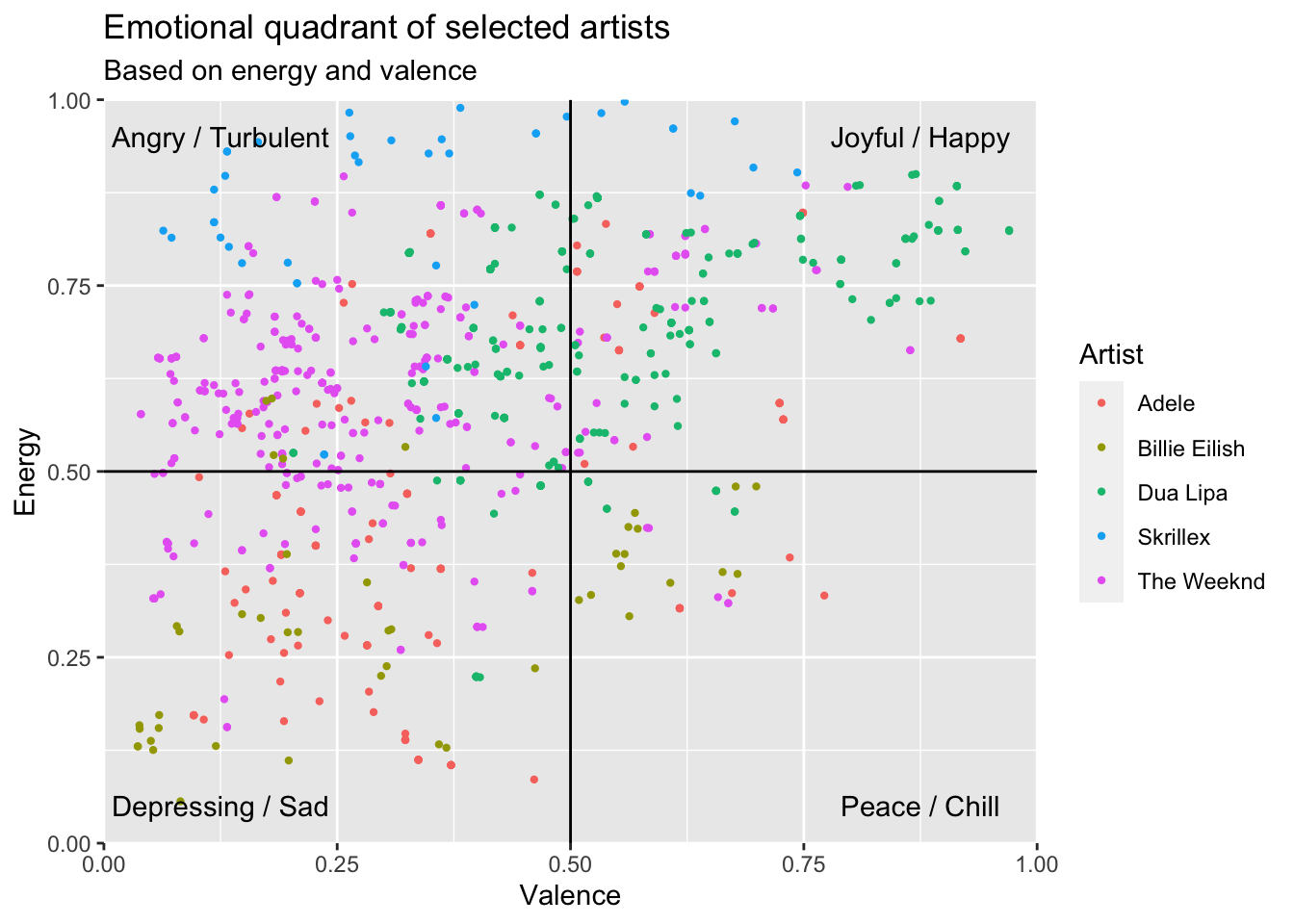
4 Album Analysen
Eine weitere Möglichkeit die uns das spotifyr Package bietet ist die Analyse von Alben. Hierzu können unter anderem folgende Funktionen genutzt werden:
- get_artist_albums - Um den Katalog eines oder mehrerer Artists zu erhalten
- get_albums - Um Informationen zu Alben mithilfe ihrer ID zu erhalten
- get_album_tracks - Um Informationen zu den Songs innerhalb bestimmter Alben zu erhalten
4.1 Album Vergleich
Durch eine Kombination der Funktionen get_album_tracks und get_track_audio_features können wir so beispielsweise Alben anhand der Audio-Features der enthaltenen Tracks vergleichen.
Vergleichen wir als Beispiel mal das Album Astroworld von Travis Scott mit dem Album Views von Drake.
Im Folgenden erstellen wir also zunächst über get_album_tracks einen Datensatz mit Informationen über die Songs im Album Astroworld von Travis Scott anhand der URI des Albums. Wir nennen diesen Datensatz astroworld_tracks.
Anschließend erstellen wir einen Datensatz mit dem Titel astroworld und benutzen eine for-Schleife, um ihn mit den Audio-Features der Songs, die wir durch die Funktion get_track_audio_features und die ID der Songs befüllen können. Die ID der Songs befindet sich logischerweise in der Spalte ID in unserem astroworld_tracks Datensatz.
astroworld_tracks <- get_album_tracks("41GuZcammIkupMPKH2OJ6I")
astroworld <-data.frame()
for (i in 1:nrow(astroworld_tracks)) {
track_data <- get_track_audio_features(astroworld_tracks$id[i])
astroworld <- rbind(astroworld, track_data)
}## Request failed [503]. Retrying in 1 seconds...Um die Tracks später in einem Datensatz mit unserem zweiten Album weiterhin Astroworld zuordnen zu können, fügen wir noch eine Spalte mit dem Namen album und dem Eintrag "Astroworld hinzu.
astroworld$album <- "Astroworld"Nun wiederholen wir die Schritte für das Album Views. Hierfür benötigen wir erneut nur die URI des Albums.
views_tracks <- get_album_tracks("40GMAhriYJRO1rsY4YdrZb")
views <-data.frame()
for (i in 1:nrow(views_tracks)) {
track_data <- get_track_audio_features(views_tracks$id[i])
views <- rbind(views, track_data)
}## Request failed [429]. Retrying in 1 seconds...Auch unseren views Datensatz müssen wir noch entsprechend des Albumtitels labeln.
views$album <- "Views"Anschließend können wir die beiden Album-Datensätze zu einem neuen Datensatz mit dem Titel album_comparison vereinen.
album_comparison <- rbind(astroworld, views)Die von uns hinzugefügten album Spalten, ermöglichen es uns nun die Audio-Features der Alben zu vergleichen. So wie im Kapitel 2.3.2 Audioanalysen stehen uns dafür verschiedene Variablen wie energy oder valence zur Verfügung.
So können wir zum Beispiel erneut einen emotional Quadrant anfertigen und die Stimmung der Songs unserer Alben vergleichen.
emotionalQuadrant <- ggplot(data = album_comparison, aes(x = valence, y = energy, color = album)) +
geom_jitter() +
geom_vline(xintercept = 0.5) +
geom_hline(yintercept = 0.5) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
scale_y_continuous(expand = c(0, 0), limits = c(0, 1)) +
annotate("text", 0.25 / 2, 0.95, label = "Angry / Turbulent") +
annotate("text", 1.75 / 2, 0.95, label = "Joyful / Happy") +
annotate("text", 1.75 / 2, 0.05, label = "Peace / Chill") +
annotate("text", 0.25 / 2, 0.05, label = "Depressing / Sad") +
labs(x= "Valence", y= "Energy") +
ggtitle("Emotional comparison of Travis Scott - Astroworld and Drake - Views", "Based on energy y valence")
emotionalQuadrant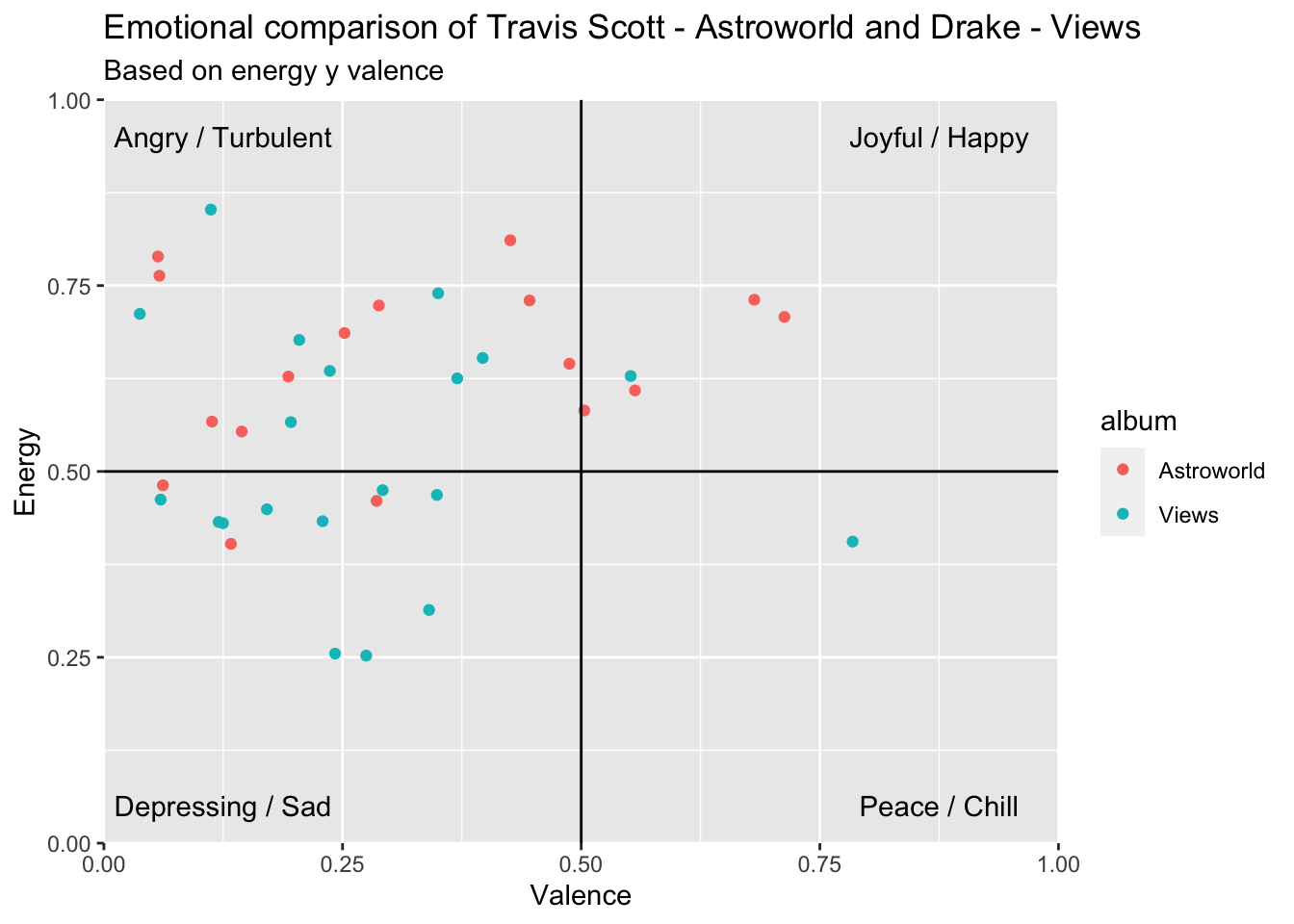
5 Weitere Ressourcen
Hilfestellungen / Dokumentationen:
Weitere Learnings/Tutorials:
Hackathon Talk “Audio Analysis with the Spotify Web API” - beinhaltet auch Hintergrundinformationen zu den Berehcnungen der Audioanalyse-Features